

来客者数と売上のデータを日々記録していて、それをExcelで散布図にしてみると、次のようになりました。
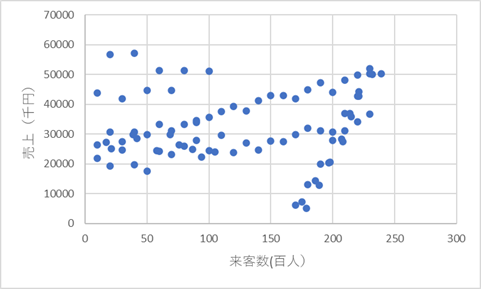
どうにも違和感のある傾向です。R-2条値を見ると、0.015と、関係があるような結果ではありません。傾きも1人入場すると19.6円ずつしか上がらないという結果です。これは入場者が200人増えても売り上げが4000円程度しか上がらないという結果です。
決してそのような傾向だとは思えません。全体的にばらついていますが、法則があるように見えます。
どうやら、いくつかのグループに分けられそうですね。
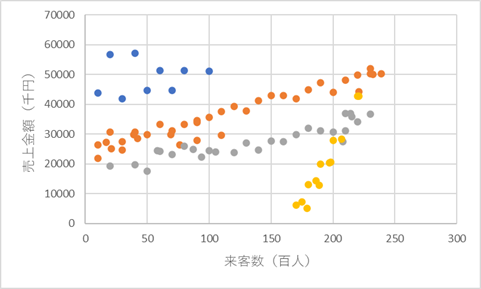
以下のように、オレンジで囲まれたグループ、黄色の直線状にあるようなグループ、青の直線状にあるようなグループ、緑の直線状にあるようなグループに分かれそうです。
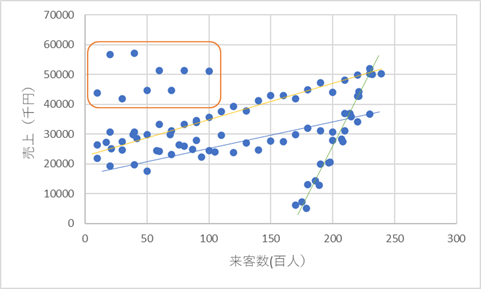
このようにグループ化した中で、R-2乗値で関係があると確かめたり、傾きを調べたりすることができ、明日は何人の入場者がいるので、いくらの売り上げになりそうだという予測ができるのです。
このようなグループ化のことをクラスター分析と呼びます。Excelではできないことの一つとされています。
今回は、このExcelではできないとされているクラスター分析をExcelでやってみる方法について紹介します。しかもわりと簡単な方法です。厳密な分析にはならない点は注意してください。
手順1:なんとなく分けてみる
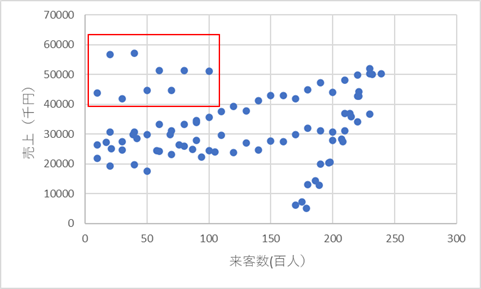
散布図を描いたら、その中にあるグループをなんとなく目でグループ化してみます。
ひとかたまりになっている部分は四角の図形で囲みましょう。四角の図形を使うのは大きなポイントです。
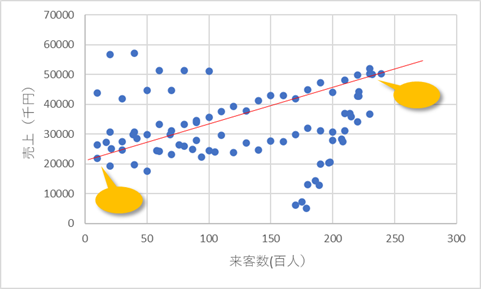
直線状に乗りそうなデータがあるのであれば直線を引いてみます。この直線は、できるだけ左右の両端に近い2点の位置ぴったりに2つの点をつなぐように描きます。
この四角、直線で描いたら、それぞれの図形を見やすいように色分けしておきましょう。
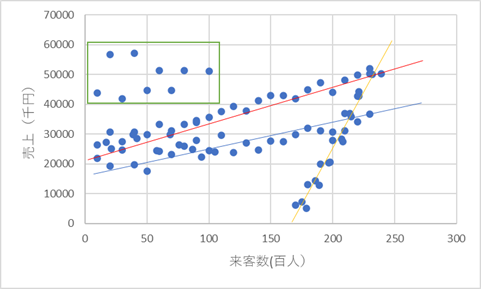
ここの精度の良さが、結果の正確さに直結しますが、あまりこだわっても仕方ないので、だいたいで合わせていきましょう。
手順2:四角で囲んだ範囲のグループを確定する
直線になっている点より、四角で囲んだ点のほうが明確にグループを成していると思います。まずこの四角で囲んだものをあるグループに確定します。複数四角で囲んだところがあるのであれば、優先順位を決めましょう。四角同士が重なって同じ点をどちらの四角に入れるか決めてしまうためです。
優先順位の高い方から、四角の左上の点と右下の点の位置を調べます。位置は、縦軸と横軸で必要なので、全部で4つの数値を読み取ります。
下の図だと、左上の点では来客数がほぼ0から始まっています。売り上げは60000が最高になっています。右下の点では来客数が105で終わっていて。売り上げが40000から始まっています。
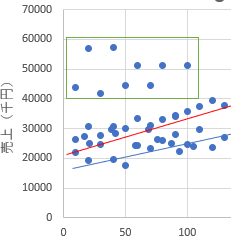
つまり、来客数は0から105まで、なおかつ売り上げが40000から60000の間にあるデータはこのグループにあるということです。非常に単純ですね。
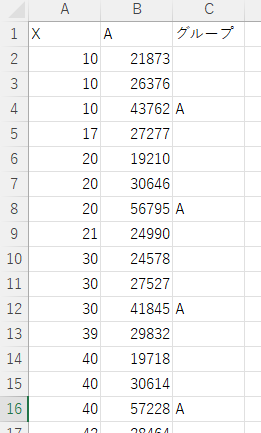
では、その実データにグループ欄を追加し、この条件に合ったデータを抜き出し、グループ名を入力します。仮の名前でいいので「A」などでよいです。ほかのデータは空白にします。
手順3:直線で結んだ範囲のグループを確定する
今度は直線で結んだ範囲をグループに分けます。直線状に乗っているかをチェックしますが、厳密に見れば、直線状に乗っている点はほとんどありません。おそらく線を結んだ2点しか直線には乗っていません。この直線からどのくらい離れたものまでをグループにするかを決めます。まずは第一段階この曲線から10%という基準にします。
この直線は、誤差がなければこの直線状に乗ったという線です。いわば理想を表しているので理想線と勝手に呼びます。その理想線は方程式を作れば、来客した人数が何人の時に売上がどのくらいになるか計算できます。
その方程式に必要なのは、1人来客があったとき売り上げが何円増えるかの「傾き」と、来場者が0人だった時の売上金額の「切片」です。切片はこのような日本語にすると、来店者がいないときは売り上げも0円じゃないかと思うのですが、これはあくまで数学的、統計的に必要な値なのです。
「傾き」はSLOPE関数、「切片」はINTERCEPT関数で求めることができます。両方とも、小さい時の入場者数と売上金額、大きい方の入場者数と売上金額を使います。
このために直線の2点は実在する点で結んでほしかったのです。また、その差が大きければ大きいほど、理想線の方程式は正確になりますので、両端に近いところを選んでもらったのです。
値はグラフにマウスを合わせると読み取ることができます。
グラフ上の読み取りたい点にマウスをクリックせずに合わせると、その値が()書きの中に表示されます。「(10, 21873)」は横軸(入場者数)が10、縦軸(売上金額)が21873であることを指します。
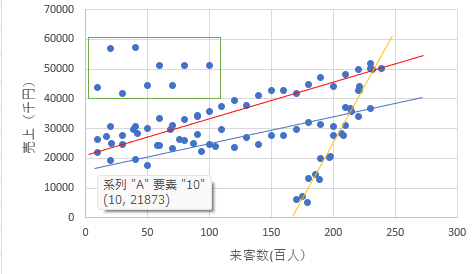
これで読み取れば、小さい方の入場者数と売上金額、大きい方の入場者数と売上金額の4つの値がわかり、この4つがあれば、SLOPE関数とINTERCEPT関数で求めることができるのです。
表の上に次の図のように、「入場者数小」「入場者数大」「売上金額小」「売上金額大」「SLOPE」「INTERCEPT」の項目を設け、「理想線1」として1つ目の理想線の方程式の結果を求める項目を追加します。そして、グラフ上から読み取った値を入力します。
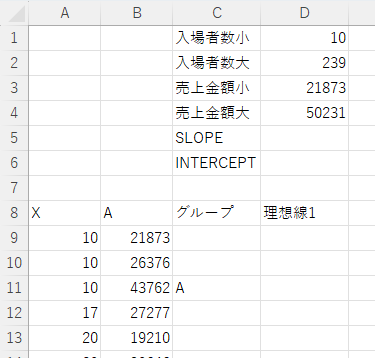
SLOPE関数も、INTERCEPT関数も引数は同じで、第一引数が縦軸のデータ範囲なので売上金額の大小のD3からD4のセル範囲、第二引数が横軸のデータ範囲なので入場者数の大小のD1からD2のセル範囲です。本来、この2つの関数はある程度大きな範囲で指定するものなのですが、今回は手で指定した2点を使うのでそれほど精度よく出せないので、最低限の大小2点のみで求めます。
今回の場合のSLOPE関数は次の計算式です。
=SLOPE(D3:D4,D1:D2)
今回の場合のINTERCEPT関数は次の計算式です。
=INTERCEPT(D3:D4,D1:D2)
この計算式を、セルD5とD6にそれぞれ入力します。
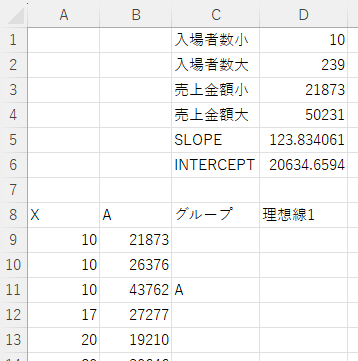
来客数が10人の時の理想線の売上金額が求められるようになりました。
理想線の売上金額は10(人数)×123.83(SLOPE関数で求めた傾き)+20635(INTERCEPT関数で求めた切片)となります。
セルC9の計算式は次のようになります。
=A9*D5+D6
コピーした場合、必ずA列は見ます。必ず5行目は見ます。必ず6行目は見ます。という形になるので、絶対参照を付けて次のような計算式にしておくと、理想線2以降の計算もこの計算式をコピーするだけで計算できます。
=$A9*D$5+D$6
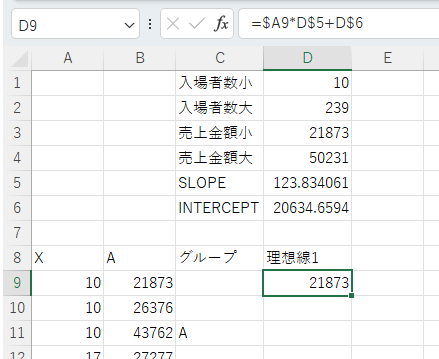
この計算式を下にコピーすれば理想線1のそれぞれの売り上げに対しての売上金額を求めることができます。
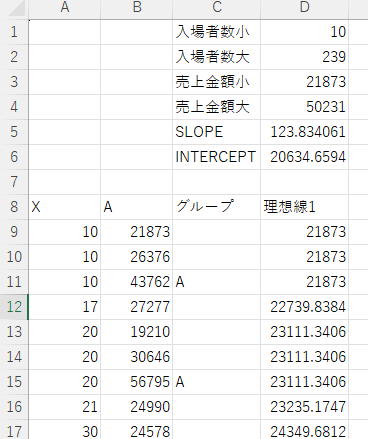
他の理想線についても同じように計算します。
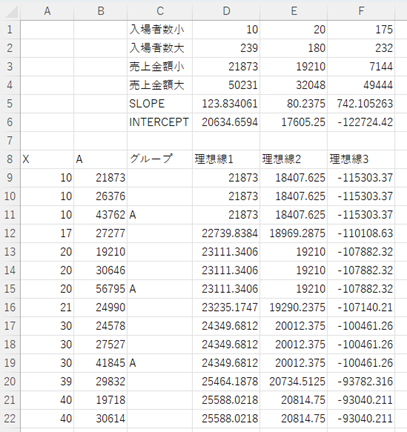
あとはそれぞれがどのグループか決定します。実際の売上金額とそれぞれの理想線の差が誤差範囲である理想線の売上金額の10%に入っているかどうかで調べていきます。
点の中には、理想線1と理想線2の両方の10%以内に入っているものも出てくるので、あらかじめ理想線1から優先してグループに入れていくことにします。
優先順位を付けてあるところに定義していく関数はIF関数を何度も使うことになるので面倒です。それが最近、IFS関数という、何個も条件を繋げられる関数が出てきました。
グループ分けがされていればそのグループ名を求めます。そうではなくて、理想線1の誤差内に売上金額があればB、さらにそうではなくて理想線2の誤差内であればC、さらにそうではなく理想線3の誤差内であればDというグループ分けをIFS関数で行います。
また理想線と実際の差は引き算で求めますがそうするとマイナスの値が入り以内かどうかの判定ができなくなるので、ABS関数でプラスマイナスを関係なく、プラスの値にすべてなるようにします。
今回、セルG9に入る計算式は次のような計算式になります。
=IFS(C9<>””,C9, ABS(B9-D9)<D9*10%,”B”,ABS(B9-E9)<E9*10%,”C”,ABS(B9-F9)<F9*10%,”D”)
そうするとどこかに分けられたものはグループが確定するのですが、そうではない場合、どれにも該当しない「#N/A」になります。
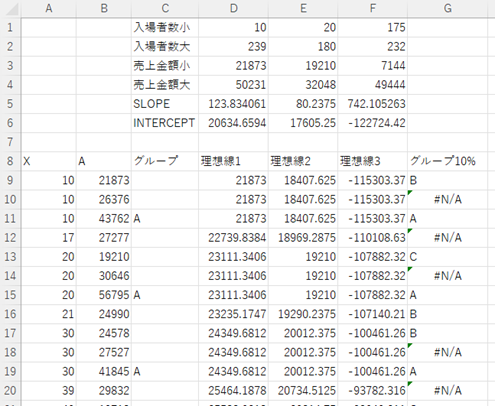
あまりにも多い時は、この決定はキープしつつ、「#N/A」の場合は、条件を20%にします。セルH9の計算式は次のようになります。
=IF(ISNA(G9),IFS(ABS(B9-D9)<D9*20%,”B”,ABS(B9-E9)<E9*20%,”C”,ABS(B9-F9)<F9*20%,”D”),G9)
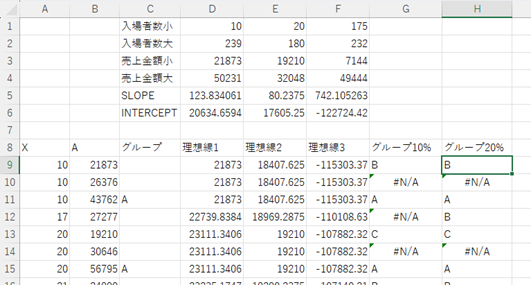
これを繰り返し、全部の値を分けていきます。
あまりに収束しない場合は、散布図を見て、目で見てグループ分けしたほうが早いかもしれえません。今回のデータでは30%まで試して88点中3点がグループに決まりませんでした。目で見て決定する場合は、今回はC列にそのグループを記載すれば、最後の列にすべてのグループが求まるようになります。
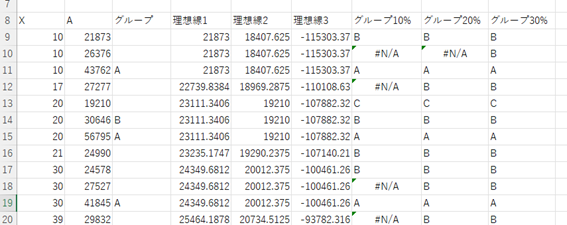
これでそれぞれのデータをグループ化でき、疑似的にではありますが、Excelで不可能といわれているクラスター分析の分類ができました。
これでグループごとに値を分析することができますね。
まとめ
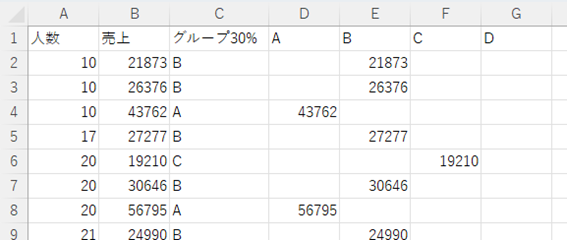
入場者数、売り上げ、最終的なグループだけのデータにして、グループごとに分けると、このような表になります。
この場合、セルD2に次の計算式が入っており、それをG列までコピーし、あとは下までコピーすることですべてのデータのグループごとの売り上げの値が入ります。
=IF($C2=D$1,$B2,””)
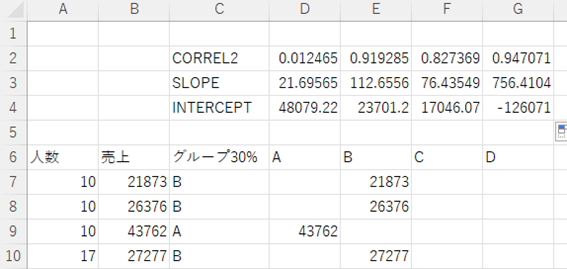
こうなればグループごとにR-2乗値を計算し相関関係を調べたり、傾きや切片を計算し、データ予測を行ったりすることもできます。
R-2乗値はCORREL2の欄です。グループAは来場者と売上金額に関係があまりなさそうですが、他のグループではとても強く関係があることがわかります。
また、そのグループに隠れた属性がないかを探すこともできます。曜日なのか、天気なのか、セール日なのか、どのような分類をすることで予測精度がさらに上がります。
また散布図をグループごとの色分けで作成でき、それぞれの特徴が明確にわかります。
本来クラスター分析は、専用のソフトを使い、統計的な手法や数学的な手法を使い、同じデータであれば誰が分析しても何回分析しても同じ結果になります。しかし、今回は理想線を手で書いています。また、それぞれのグループ分けの優先順位も勝手につけているので、分析する人によってそれらは変わりますので、繰り返し同じ値は再現するとは限りません。
そのような意味ではちゃんとしていないので、これを根拠に何かを予測するとき、保証されるものではありません。
しかし、このくらいの手間だけで手軽にクラスター分析っぽいことができるのは、とてもすごいことのような気がします。
今回、伝えたかった一番のテーマは、Excelを使えば何とかなるものだということです。初めからあきらめないで、なんとかできないかと探り探り、本当に正しいやり方ではなくても近いところまで、この方法ならできると考えられる力はビジネスにおいてとても大事です。そのためには想像力も必要ですし、Excelでいろいろなことができるというスキルも必要です。組み立てる力も必要です。それらすべてを今すぐ網羅するのは大変なので、日ごろから少しずつ楽しみながらスキルアップしていくことが重要です。

