

Excelには「重複の削除」という、一覧表から同じデータは重複させないで取り出す機能があります。データタブの中の重複の削除でできます。
これが新しいExcelではUNIQUE関数という関数で実現できます。
関数で重複の削除ができると、操作し忘れすることがなくなり、元データを変更するだけで重複が削除されたデータを作成することができます。
しかし、Excel2016では関数で行うことができないので、重複データを削除するには、重複の削除やピボットテーブルを使う必要があり、操作し忘れする危険が残ります。
そこで、計算式で重複を削除するテクニックを紹介します。
COUNTIF関数
重複しているかどうかを検出するには、その値が範囲の中で1つしかないのかどうかで判断できます。
1つしかないのであれば重複なし、複数ある場合は重複データとなります。
上からの範囲を見ていって、はじめて登場した値は1つめになるはず、初めてではない場合は2以上になりますね。
これを検出できるのがCOUNTIF関数です。
COUNTIF関数の書式は次の通りです。
=COUNTIF(範囲,値)
範囲は上から現在位置までの範囲、値は何個目か調べる値になります。
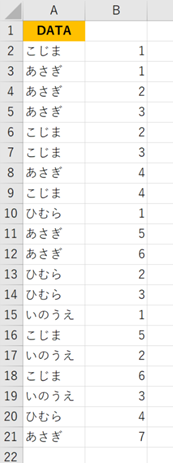
上記のB列は、セルB2に次の計算式を入力し、下にコピーしています。
=COUNTIF($A$1:A2,A2)
この値が1の行が重複していないものなので、1であるたびに1ずつ増える、1ではない場合はそのままの値とするIF関数を使います。
=IF(COUNTIF($A$2:A2,A2)=1,B1+1,B1)
1なら上のセル値に1を足す、そうでなければそのままの値にします。この計算式をセルB2に入力し、コピーします。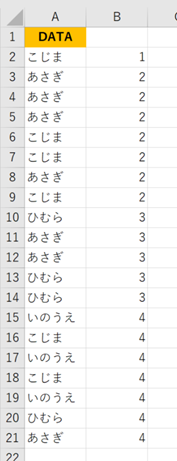
INDEX関数とMATCH関数で初めて登場したところを検出
あとは、1から4に対する値をINDEX関数とMATCH関数で探します。
2や4の値は複数ありますが、MATCH関数の完全一致は、上から見て初めてその値が出たところを指し示すので、普通にMATCH関数を使えばよいです。
INDEX関数とMATCH関数の組み合わせは次の書式です。
=INDEX(最終的に表示したい列,MATCH(探したい値,探したい列,0))
今回の場合、セルD2に求める場合は、探したい値は1から始まる番号なので行番号を取り出すROW関数を使ってそこから1引いたものにします。
また、下にコピーしていくと、今回の場合は4以上の数値がなく、エラーになるので、IFERROR関数で空白を表示するようにします。
=IFERROR(INDEX($A$2:$A$21,MATCH(ROW()-1,$B$2:$B$21,0)),””)
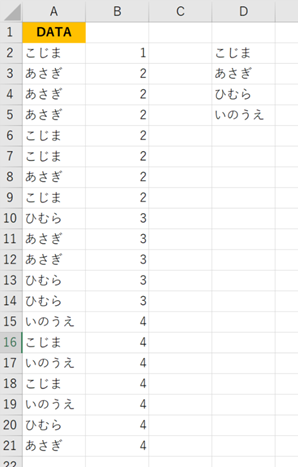
あとはセルD2の計算式をコピーするだけです。
複数列に渡る重複の削除
複数列の重複の削除も応用でできます。
方法は2つあります。
ひとつは複数条件の個数を数えるCOUNTIFS関数を使います。
次の例では、セルC2に次のCOUNTIFS関数からなる条件式が入っています。
=IF(COUNTIFS($A$1:A2,A2,$B$1:B2,B2)=1,C1+1,C1)
セルE2にはセルC列を参照したA列の値を求めるINDEX関数とMATCH関数、セルF2には同じくB列を求めるものが入っています。
=IFERROR(INDEX($A$2:$A$21,MATCH(ROW()-1,$C$2:$C$21,0)),””)
=IFERROR(INDEX($B$2:$B$21,MATCH(ROW()-1,$C$2:$C$21,0)),””)
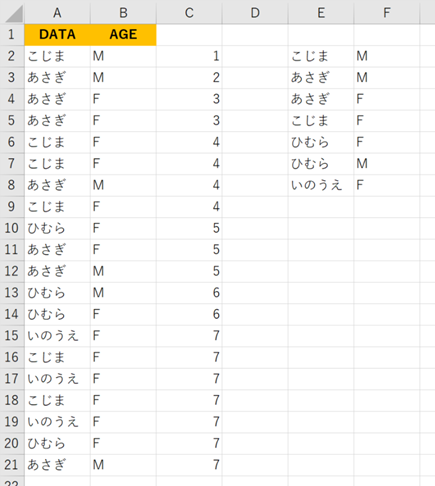
もう一つは、元データの文字列を行ごとに結合してしまう列を用意して、COUNTIF関数でその列で初めて登場したか検出します。
セルC2にセルA2とB2の文字を結合したものを用意して、それで初めて出てきたか検出する方法です。
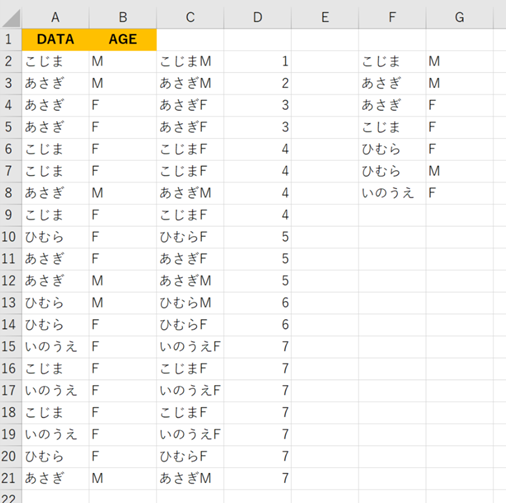
この方法であればCOUNTIFS関数が使えない古いExcelでも使えます。
そのようなExcelはもうサポートが切れているので本来は使うべきではないのですが、お客さんが使っているとそういうケースに対応せざるを得ないですね。
まとめ
重複の削除を計算式でもできるし、かなり古いExcelでも使えるような単純な計算式でも使えるような方法を紹介しました。
今回の方法でも計算式は手作業でコピーしなければならなくなるのですが、データ範囲をテーブルにしておけばデータが追加されるたびに自動で計算式も入ってくるのでテーブルに設定しましょう。
これで求めたものは、単純な重複の削除がされたデータとしても使えますし、SUMIFなどでピボットテーブルのようなものを計算式で作るということにも応用できます。

コメント